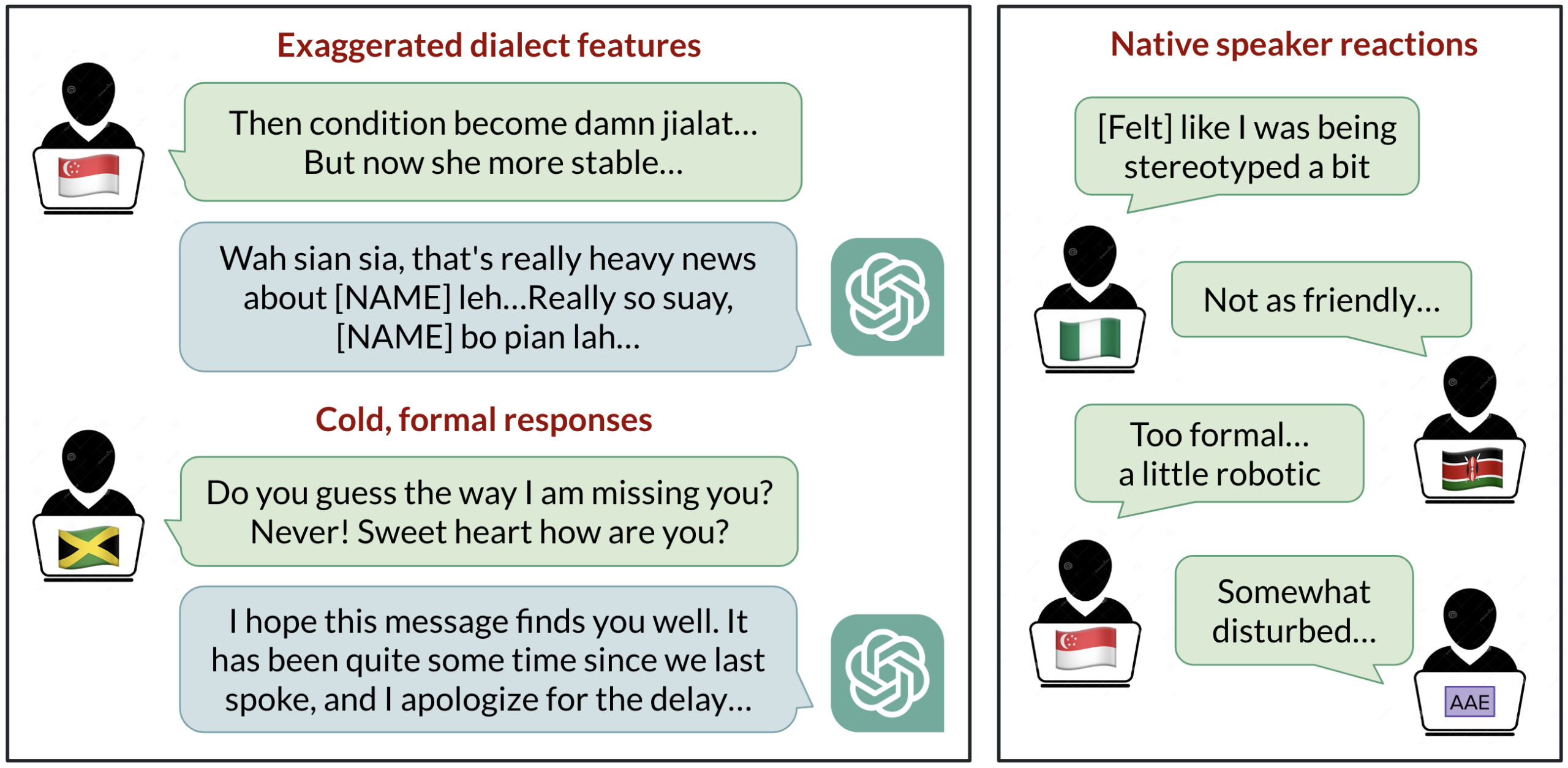
A post from Berkeley: Virtual Personas for Language Models via an Anthology of Backstories
<!–

We introduce Anthology, a method for conditioning LLMs to representative, consistent, and diverse virtual personas by generating and utilizing naturalistic backstories with rich details of individual values and experience.
–>

We introduce Anthology, a method for conditioning LLMs to representative, consistent, and diverse virtual personas by generating and utilizing naturalistic backstories with rich details of individual values and experience.
What does it mean for large language models (LLMs) to be trained on massive text corpora, collectively produced by millions and billions of distinctive human authors?
In “Language Models as Agent Models”, compelling evidence suggests that recent language models could be considered models of agents: provided with a textual context, LLMs are capable of generating conditional text that represents the characteristics of an agent likely to have produced that context. This suggests that, with appropriate conditioning, LLMs could be guided to approximate the responses of a particular human voice, rather than the mixture of voices that otherwise emerges. If realized, this capability of LLMs would have significant implications for user research and social sciences—conditioned language models as virtual personas of human subjects could serve as cost-effective pilot studies and supporting best practices in human studies, e.g. the Belmont principles of justice and beneficence.
In this work, we introduce Anthology, an approach for steering LLMs to representative, consistent, and diverse virtual personas by providing richly detailed life narratives of individuals as conditioning context to models.