Posted inAI Amazon RSS A post from Amazon AWS : Reducing hallucinations in large language models with custom intervention using Amazon Bedrock Agents Posted by By 26. November 2024 Hallucinations in large language models (LLMs) refer to the phenomenon where the LLM generates an…
Posted inAI Amazon RSS A post from Amazon AWS : Deploy Meta Llama 3.1-8B on AWS Inferentia using Amazon EKS and vLLM Posted by By 26. November 2024 With the rise of large language models (LLMs) like Meta Llama 3.1, there is an…
Posted inAI Amazon RSS A post from Amazon AWS : Serving LLMs using vLLM and Amazon EC2 instances with AWS AI chips Posted by By 26. November 2024 The use of large language models (LLMs) and generative AI has exploded over the last…
Posted inAI Amazon RSS A post from Amazon AWS : Using LLMs to fortify cyber defenses: Sophos’s insight on strategies for using LLMs with Amazon Bedrock and Amazon SageMaker Posted by By 26. November 2024 This post is co-written with Adarsh Kyadige and Salma Taoufiq from Sophos. As a leader…
Posted inAI Amazon RSS A post from Amazon AWS : Enhanced observability for AWS Trainium and AWS Inferentia with Datadog Posted by By 26. November 2024 This post is co-written with Curtis Maher and Anjali Thatte from Datadog. This post walks…
Posted inAI Amazon RSS A post from Amazon AWS : Create a virtual stock technical analyst using Amazon Bedrock Agents Posted by By 26. November 2024 Stock technical analysis questions can be as unique as the individual stock analyst themselves. Queries…
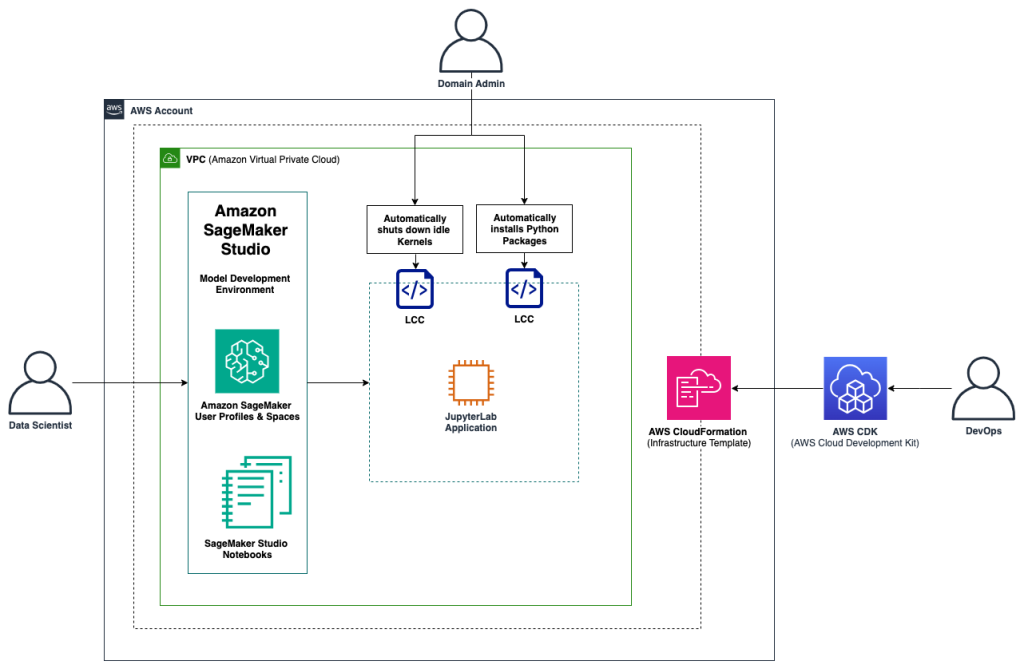
Posted inAI Amazon RSS A post from Amazon AWS : Apply Amazon SageMaker Studio lifecycle configurations using AWS CDK Posted by By 26. November 2024 This post serves as a step-by-step guide on how to set up lifecycle configurations for…
Posted inAI Amazon RSS A post from Amazon AWS : Build a read-through semantic cache with Amazon OpenSearch Serverless and Amazon Bedrock Posted by By 26. November 2024 In the field of generative AI, latency and cost pose significant challenges. The commonly used…
Posted inAI Amazon RSS A post from Amazon AWS : Rad AI reduces real-time inference latency by 50% using Amazon SageMaker Posted by By 26. November 2024 This post is co-written with Ken Kao and Hasan Ali Demirci from Rad AI. Rad…
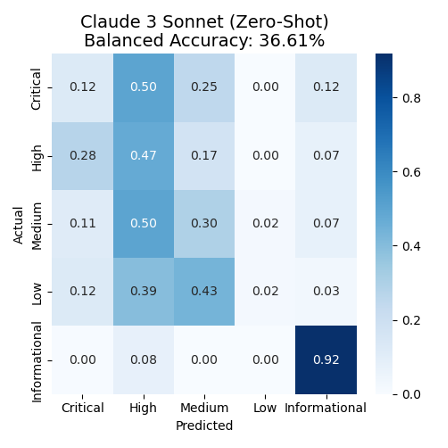
Posted inAI Amazon RSS A post from Amazon AWS : Read graphs, diagrams, tables, and scanned pages using multimodal prompts in Amazon Bedrock Posted by By 26. November 2024 Large language models (LLMs) have come a long way from being able to read only…