Recommended: Nvidia Unveils Latest AI Chip, the Blackwell
We recommend this AI post “Nvidia Unveils Latest AI Chip, the Blackwell” on #Medium Read…
As computer vision researchers, we believe that every pixel can tell a story. However, there seems to be a writer’s block settling into the field when it comes to dealing with large images. Large images are no longer rare—the cameras we carry in our pockets and those orbiting our planet snap pictures so big and detailed that they stretch our current best models and hardware to their breaking points when handling them. Generally, we face a quadratic increase in memory usage as a function of image size.
Today, we make one of two sub-optimal choices when handling large images: down-sampling or cropping. These two methods incur significant losses in the amount of information and context present in an image. We take another look at these approaches and introduce $x$T, a new framework to model large images end-to-end on contemporary GPUs while effectively aggregating global context with local details.
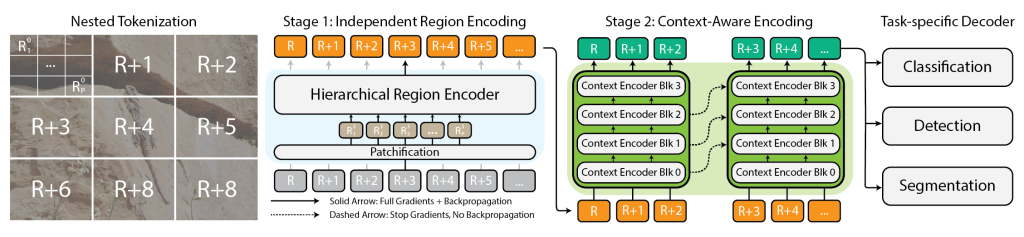
Architecture for the $x$T framework.